Documents and images your systems can finally read.
Scanned Arabic and English paperwork becomes governed, searchable, citable knowledge. Images flowing through chat and workflows get read, checked, and acted on. Built for the stamps, skew, and mixed-language mess of real archives, not for pristine samples.
- Arabic + English OCR
- Page-accurate provenance
- Vision in chat & workflows
- Human review built in
From scan to accountable answer.
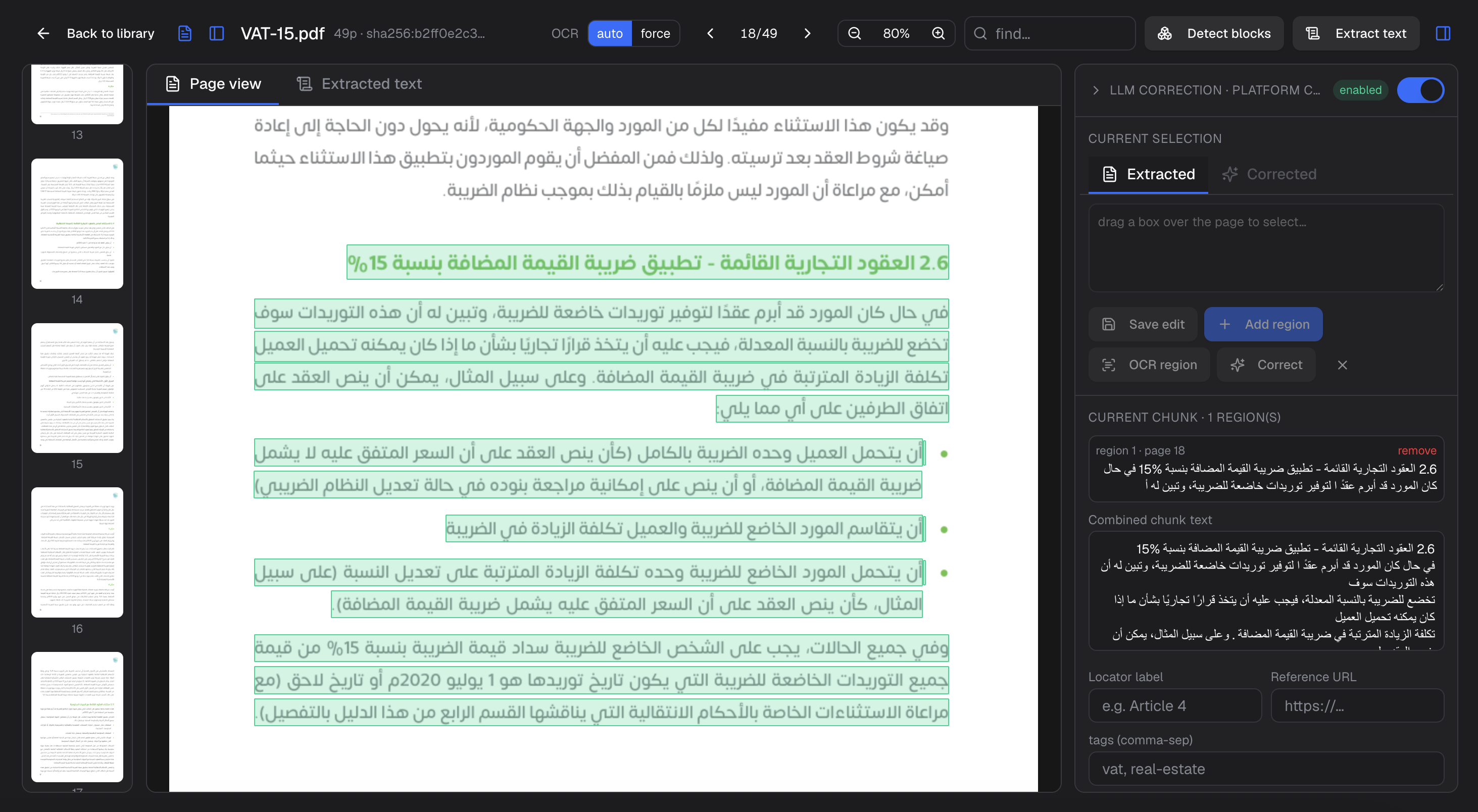
Recognition is the easy half. The work is keeping every extracted fact tied to the exact spot on the exact page it came from.
OCR that survives real paperwork
Skewed scans, stamps, tables, and Arabic and English on the same page. Recognition runs with language-model repair for degraded text, and the page coordinates of every span are preserved, so an extracted clause still points at its exact location in the source.
From scan to cited knowledge
Extracted content flows into the same review-then-publish pipeline as every other source: drafts a person approves, structure and lifecycle on each record, and answers that cite the page rather than vaguely referencing a file.
Vision inside conversations
A customer sends a photo of a form, an invoice, or an ID page over WhatsApp or the web widget. The assistant reads it, checks it against the rules, and answers, in the same conversation.
Vision steps inside workflows
A workflow step that looks at an image and decides: classify the submission, verify a document is complete, extract the fields, or flag it for a person. Vision becomes a governed step in a process, not a separate science project.
Custom vision models where they earn their place
Detection and classification for domain-specific needs, trained and evaluated on your imagery, deployed inside your perimeter, and wrapped in the same review and audit discipline as everything else.
We start with your worst documents, on purpose.
Sample audit
Give us your ugliest scans, not your cleanest. We measure recognition quality on them first and tell you what is achievable before you spend.
Pilot pipeline
A working scan-to-knowledge pipeline on a real document class, with accuracy measured span by span.
Accuracy hardening
Measure, fix the data, tune, repeat. The low-confidence tail routes to human review instead of silently corrupting your knowledge.
Production and review workflow
The pipeline goes live with a review queue, provenance on every record, and reporting on throughput and confidence.
Real scans, real coordinates.
An archive that answers questions.
- An OCR pipeline measured on your own documents
- An extraction accuracy report, class by class
- A human review workflow for the low-confidence tail
- Page-level provenance on every extracted fact
- A production deployment inside your perimeter
Sovereign, Arabic-first AI, ready to prove its value on-premises, in weeks.
Start with one high-value use case and measure it on real data.